
发布日期:2025-01-02 16:23 点击次数:128

本文作家来自清华大学、字节特别、中科院自动化所、上海交通大学和新加坡国立大学。作家列表:李兴航、李沛言、刘明桓、王栋、刘济榕、康炳易、马骁、孔涛、张翰博和刘华平。第一作家李兴航是清华大学缱绻机系博士生。通信作家是字节特别机器东说念主商讨员孔涛日本萝莉,新加坡国立大学博士后张翰博和清华大学缱绻机系讲解刘华平。
频年来,视觉谈话基础模子(Vision Language Models, VLMs)大放异彩,在多模态连气儿和推理上展现出了超强才智。当今,愈加酷炫的视觉谈话手脚模子(Vision-Language-Action Models, VLAs)来了!通过为 VLMs 加上手脚预测模块,VLAs 不仅能 “看” 懂和 “说” 清,还能 “动” 起来,为机器东说念主领域开启了新玩法!
掀开新闻客户端 升迁3倍宗旨度天然 VLAs 在各式任务和场景中进展拉风,但大众在模子联想上却走了好多不同的路,比如用什么架构、如何选数据、如何调磨真金不怕火政策等等,这导致领域内对 “如何作念好一个 VLA” 还莫得融合的谜底。为了理清这些问题,咱们通过一系列的践诺,提议了一个全新模子 ——RoboVLMs。

论文标题:Towards Generalist Robot Policies: What Matters inBuilding Vision-Language-Action Models
论文地址:https://arxiv.org/pdf/2412.14058
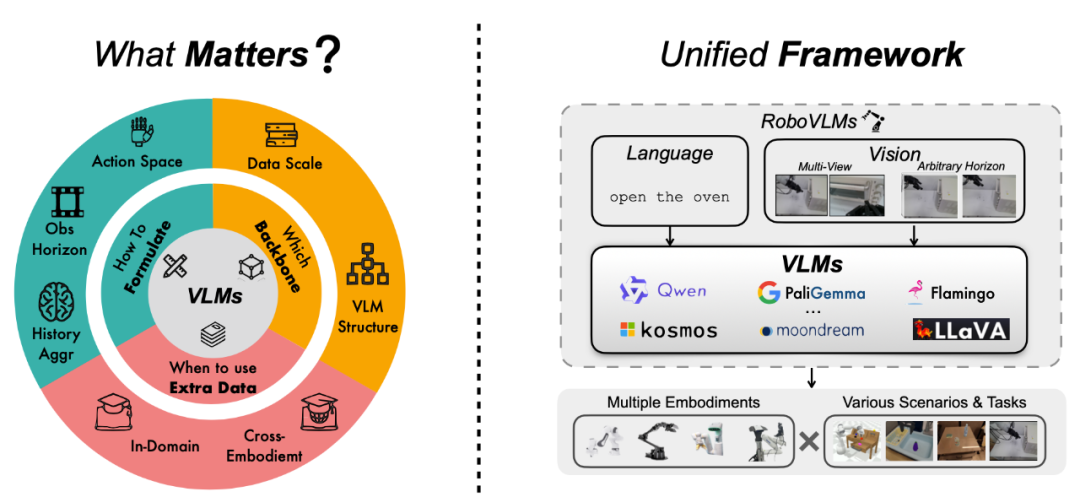
这个模子超等粗浅,但性能却非常硬核!它不仅在三个模拟任务中得回了高分,还在果真机器东说念主践诺中交出了满分答卷。这篇著作即是要带你一皆望望,咱们是如何用 RoboVLMs 解锁 VLA 的无尽可能!
快播在线观看四大灵魂拷问:RoboVLMs 是如何真金不怕火成的?
咱们围绕四个要津问题,对 VLA 的联想张开了深度探索,底下就带你望望谜底!
1. 为什么要用 VLA 模子?
粗浅说,通过践诺,咱们发现联想合理的 VLA 不仅能罅隙责罚常见的操作任务,还能在生分场景中稳稳施展。
仿真任务中拿下顶尖成绩
在 CALVIN 和 SimplerEnv 环境里,RoboVLMs 得回了压倒性的胜利:
任务见遵守:进展空闲且超越主流模子。
泛化才智:即使在生分场景中,进展依然抗打!
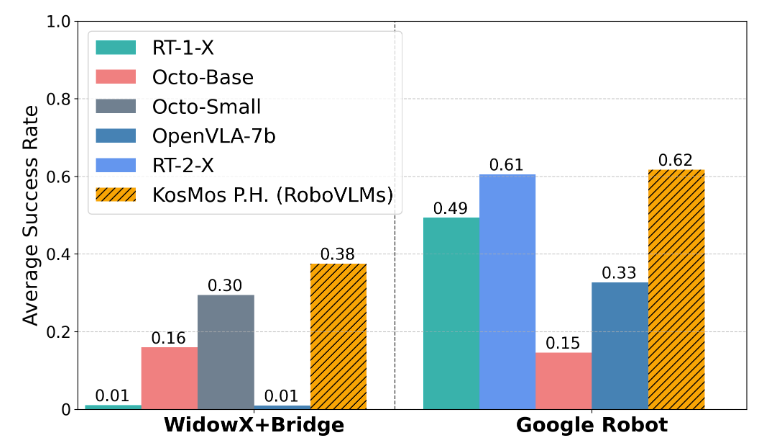
图 1 SimplerEnv 仿真环境中的评测结果
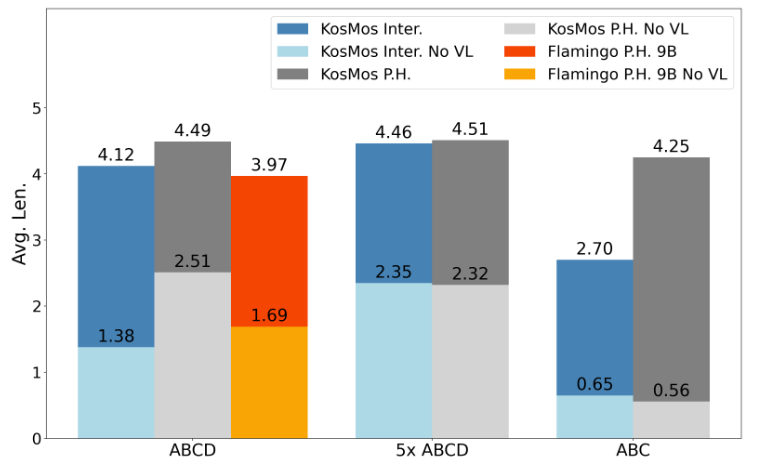
图 2 针对视觉谈话预磨真金不怕火的消融践诺结果日本萝莉


果真机器东说念主践诺也不输
在果真环境中,RoboVLMs 靠近更复杂的挑战,仍然比其他模子进展更好。比如,在果蔬分类任务中,它不仅能精确识别,还能应付干涉环境,稳稳完要素类操作。不管是已知场景照旧新任务,它都能罅隙拿下。
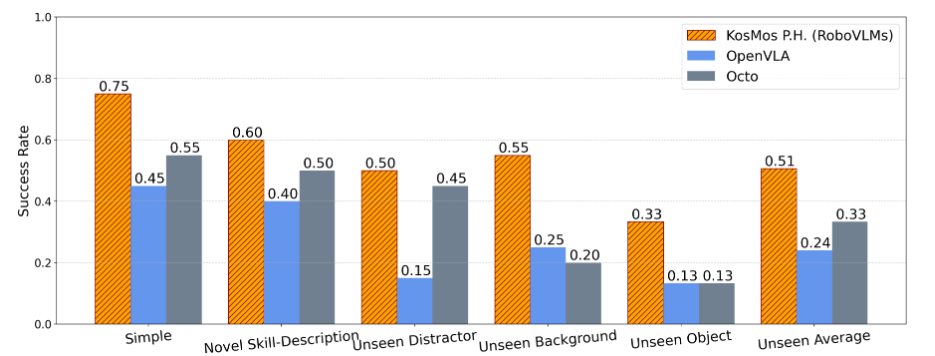
图 3 果真环境下的评测结果
关于未见过的手段刻画、布景、干涉物体和研讨物体,RoboVLMs 均能很好的完成任务。

2. 如何联想一个靠谱的 VLA 架构?
这里面认真可不少!比如:
手脚空间:用连气儿手脚空间比碎裂的好好多。
历史信息:增多步历史信息后,模子的操作更稳准狠。
历史信息组织模块:一个特地的模块不错让模子更懂 “高下文”。
经由一系列践诺,咱们阐明了这些联想禁受是升迁模子性能和泛化才智的要津。进一步的践诺也标明,最优的联想来自于基于 KosMos 基座模子的架构,而且皆集了特地的历史信息组织模块。这么的联想在 CALVIN 中终光显出色的泛化才智,在 zero-shot 成就下仅有幽微的性能着落,而其他联想面容的模子则出现了显赫掉分。这一论断平直说明,架构联想的犀利对模子的泛化才智和遵守至关报复。
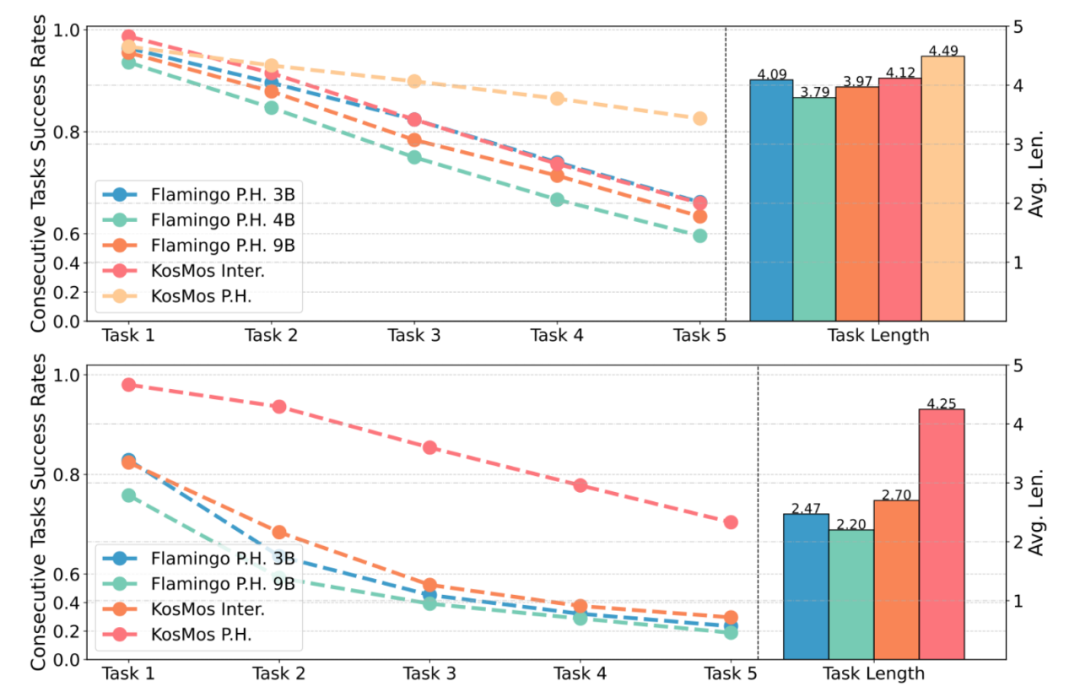
3. 选什么基座模子最符合?
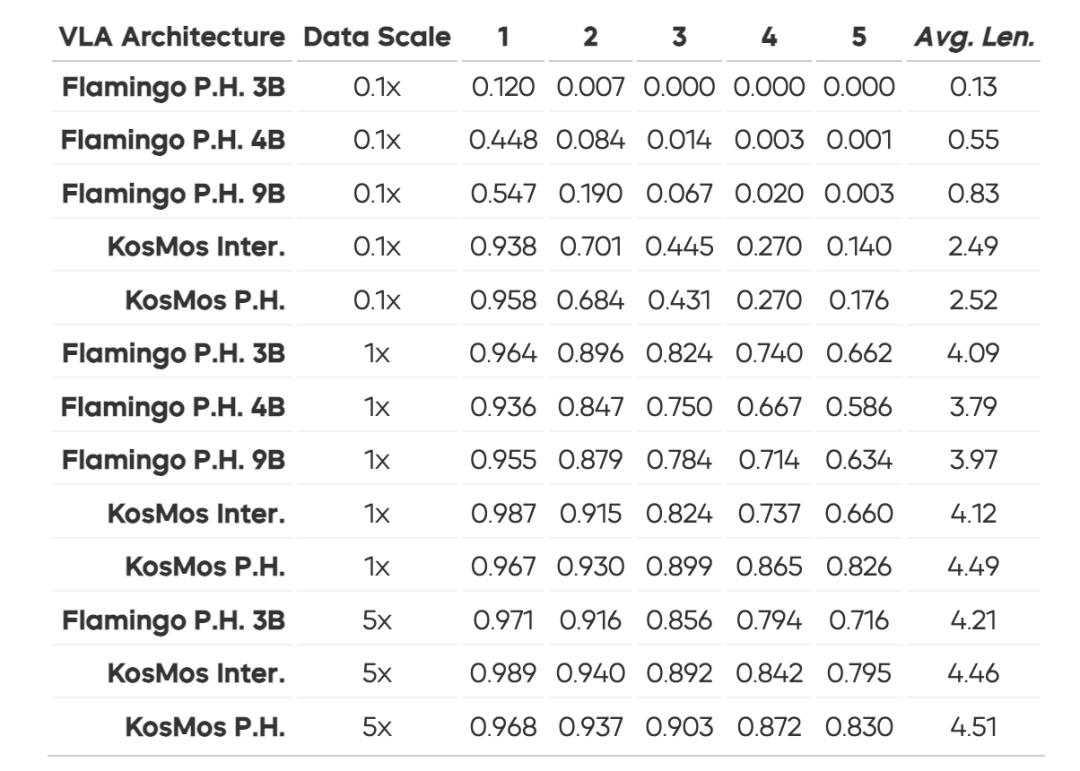
咱们对比了现时主流的 8 种视觉谈话模子(VLM),结果发现 KosMos 和 Paligemma 的进展遥遥率先,罅隙碾压其他模子。不管是任务完成的精确度照旧泛化才智,它们都展现出了压倒性的上风。究其原因,主要收获于它们经由了塌实且全面的视觉谈话预磨真金不怕火,从而为模子提供了宏大的先验常识和连气儿才智。
这一发现让咱们愈加服气:选对基座模子,即是让 VLA 模子升起的要津一步!念念要让模子在多模态任务中进展惊艳,一个经由深度预磨真金不怕火、具备宏大视觉谈话表征才智的 VLM 基座彰着能提供无与伦比的助力。而一朝打好了这个基础,后续的联想和磨真金不怕火才智信得过施展最大后劲。
4. 跨本色数据什么本领加入最符合?
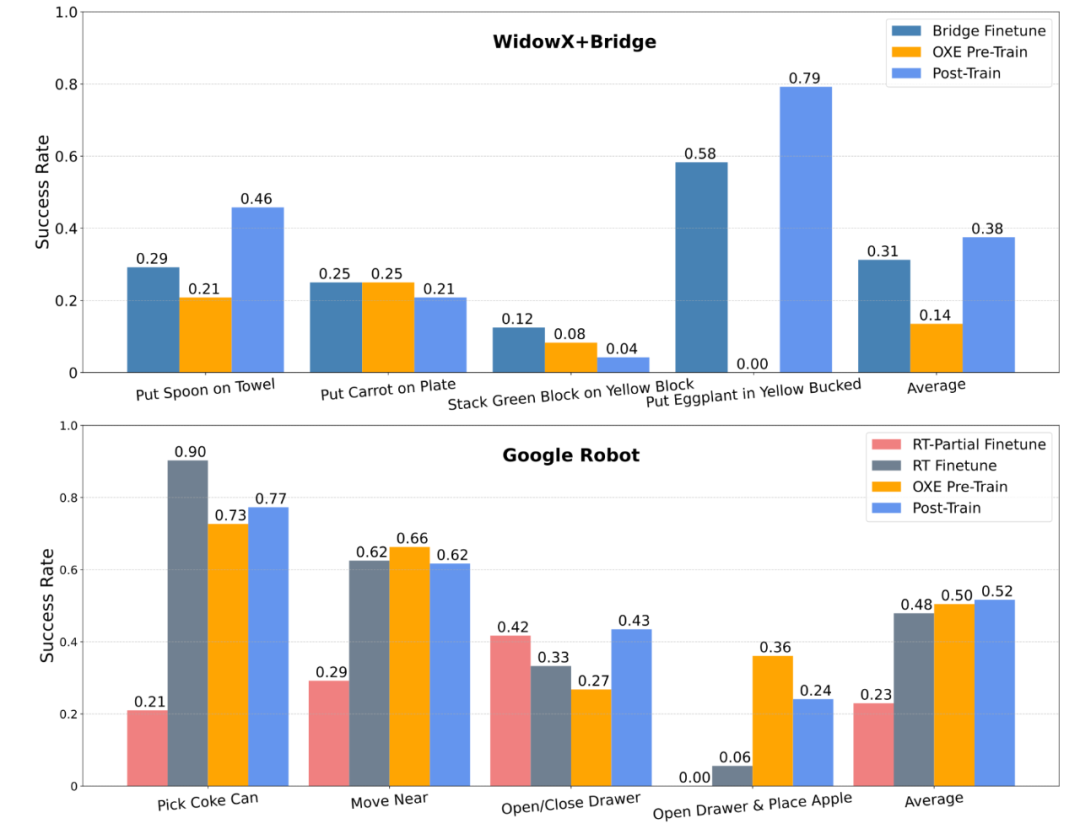
践诺告诉咱们一个黄金端正:在预磨真金不怕火阶段引入跨本色数据(如 Open-X Embodiment 数据集)不错显赫升迁模子的鲁棒性和少样本场景下的进展。反之,平直将跨本色数据和微调数据搀和磨真金不怕火,后果就没那么显赫了。这些论断为将来 VLA 模子的磨真金不怕火政策指明了所在。
具体践诺中,咱们在 WidowX+Bridge 和 Google Robot 两大环境下差别进行了不同磨真金不怕火政策的测试:
WidowX+Bridge 环境:
Bridge Finetune:平直在竣工的 Bridge 数据集上微调(测试任务不包括在内)。
OXE Pre-Train:先用 OXE 数据集预磨真金不怕火模子。
Post-Train:用经由 OXE 预磨真金不怕火的模子再在 Bridge 数据集上微调。
Google Robot 环境:
RT-Partial Finetune:仅在特定的 RT 任务上微调。
RT Finetune:在竣工的 RT 数据集上微调(包括测试任务)。
OXE Pre-Train:先用 OXE 数据集预磨真金不怕火模子。
Post-Train:在 OXE 预磨真金不怕火基础上用 RT 数据集进一步磨真金不怕火。
践诺结果进一步考证了:在预磨真金不怕火阶段引入跨本色数据不仅能升迁泛化才智,还能让模子在少样本和高复杂任务下进展更佳。
预测将来:VLA 的进阶之路
天然 RoboVLMs 还是很能打了,但接下来的发展空间更让东说念主期待!将来不错探索:
更细化的联想优化:比如再打磨 VLM 里面结构、信息会通模块和磨真金不怕火研讨,让它更高效。
挑战复杂任务:像 “作念早餐” 这种长链条任务,也许是下一个冲破点!
多模态互助才智:进一步让机器东说念主 “看懂”、“听清”、“动得更忠良”。
RoboVLMs 的出现日本萝莉,考证了视觉谈话手脚模子的可能性,也让机器东说念主更接近成为咱们的万能助手。将来,它们大概不仅能连气儿谈话和视觉,还能信得过帮咱们完成那些繁琐又复杂的任务。接下来会有更多惊喜等着咱们!

